Back when re-engineering was all the rage, a reported 70% of all re-engineering projects failed.
That’s in contrast to the shocking failure rate I ran across a few years later for CRM implementations, 70% of which failed.
On the other hand, the statistic tossed around for mergers and acquisitions is that 70% don’t work out.
On the other hand, the most recent numbers for large application development projects show that, in round numbers, 70% have results in the disappointing to failed completely range.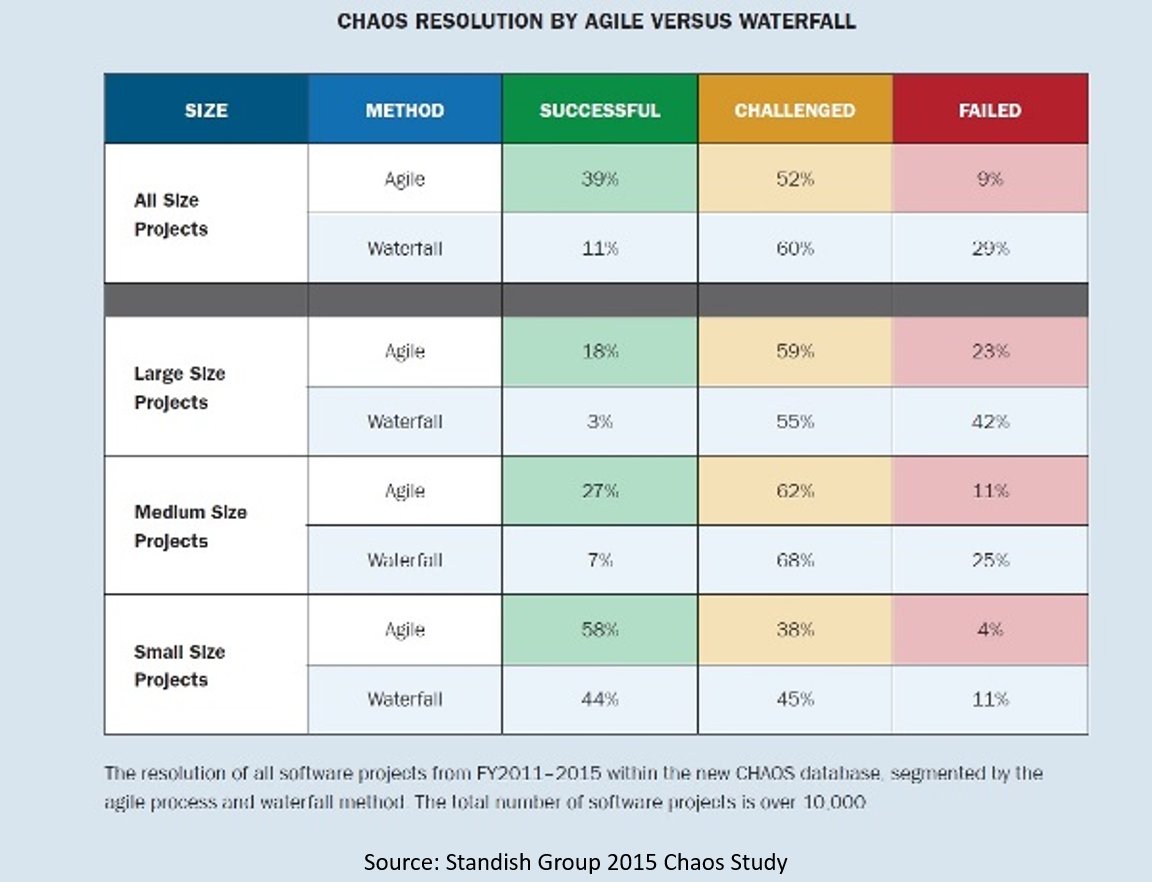
At least, that’s the case for large application development projects executed using traditional waterfall methods, depending on how you count the “challenged” category.
And oh, by the way, just to toss in one more related statistic, even the best batters in baseball fail at bat with a failure rate of just about 70%.
What’s most remarkable is how often those who tabulate these outcomes are satisfied with the superficial statistic. 70% of re-engineering projects fail? There must be something wrong with how we’re executing re-engineering projects. 70% of CRM implementations fail? What’s wrong with how we handle these is a completely different subject.
As are the M&A, application development, and baseball at-bat percentages.
But they’re not different subjects. They are, in fact, the exact same subject. Re-engineering, customer relationship management, mergers and acquisitions, and hitting a pitched baseball are all intrinsically hard challenges.
And, except for hitting a baseball, they’re the same hard challenge. They’re all about making significant changes to large organizations.
Three more statistics: (1) Allocate half of all “challenged” projects to “successful” and half to “failed” and it turns out more than 75% of all small Agile application development projects succeed; (2) anecdotally, 100% of all requested software enhancements complete pretty much on schedule and with satisfactory results; and (3) during batting practice, most baseball players hit most of the balls pitched to them.
Okay, enough about baseball (but … Go Cubbies!).
Large-scale organizational change is complex with a lot of moving parts. It relies on the collaboration of large numbers of differently self-interested, independently opinionated, and variably competent human beings. And, like swinging a bat at a pitch, it’s aimed at an unpredictably moving target.
The solution to the high organizational change failure rate is very much like how to not get hurt when driving a car at high speed into a brick wall: Don’t do it.
The view from here: Extend Agile beyond application development, so large scale change becomes a loosely coupled collection of independently managed but generally consistent small changes, all focused on the same overall vision and strategy.
Turns out, I wrote about this quite some time ago — see “Fruitful business change,” (KJR, 5/26/2008) for a summary of what I dubbed the Agile Business Change (ABC) methodology.
I’ll provide more specifics next week.
* * *
Speaking of not providing more specifics, here’s this week’s Delta progress report:
Gil West, Delta’s COO, has been widely quoted as saying, “Monday morning a critical power control module at our Technology Command Center malfunctioned, causing a surge to the transformer and a loss of power. When this happened, critical systems and network equipment didn’t switch over to backups. Other systems did. And now we’re seeing instability in these systems.”
That’s all we have. Two weeks. Three sentences. Near-zero plausibility.
Leading to more information-free speculation, including lots of unenlightened commentary about Delta’s “aging” technology, even though this can’t have had anything to do with it. Delta’s actual hardware isn’t old and decrepit, nor is anyone suggesting the problem was a failed chip in its mainframes. Delta’s software may be old, but if it ran yesterday it will run tomorrow, unless an insufficiently tested software change is put into production today.
Nor does a loss of power cause systems to switch over to backups. It causes the UPS to kick in and keep everything running until the diesel generators fire up. Oh, and by the way, much smaller businesses than Delta are smart enough to have power supplied by two different substations, entering through two different points of presence, feeding through different transformers, so as to not have a single point of failure.
But because nobody is insisting on detailed answers from Delta, it’s doubtful we’ll ever know what really happened.
Which, in the greater scheme of things, probably doesn’t matter all that much, other than leading us to wonder how likely it is to happen again.
1. Thanks for sharing the statistics on the 2 approaches. I just hope that the IT folks using these statistics realize that some of the “a priori” oriented people really won’t understand what the statistics are actually saying because these numbers will seem abstract to them, even though they seem like concrete to me.
2. On the Delta mystery. I worked as a maintenance man, specifically a journeyman stationary engineer, for 17 years, before and during transitioning into programming.
Part of my professional responsibilities was checking that the emergency power supply functions were working. Like ground nutrients needed by a tree, electrical power comes in from the power company through a transformer to one or more main circuit breakers to be distributed up through the building through branches, each of which is protected by one or more levels of circuit breakers.
No computer operations can create a load that would cause a surge past the main circuit breakers that would in any way cause a main transformer failure. The only thing that I know of that could cause a transformer failure would be a “dead short” between 2 of the 3 power busses that feed a large power consumer.
I happen to know this in detail because I worked in a large office building where the chief engineer apparently browbeat a young electrician into working overtime hours on to check one of our large circuit breakers, while it was still powered up. We don’t know what happened, but our best guess is that he was fatigued after working for 18 hours straight and dropped a wrench that landed flat on 2 buss bars creating a dead short.
It set the transformer on fire and the young electrician got 3rd degree burns over 80% of his body. Unfortunately, it took him 6 weeks to die. He left a wife and 2 small children.
The battle for IT to get proper funding is familiar to me from the battles the chief engineers had to fight to keep maintenance staffing at proper levels. Time and time again, some new high management exec would come in boasting about how much money he could save because maintenance costs were “too high”, only to be proven by events that every penny was needed by maintenance.
I hope somebody checks into this, because there is a chance that somebody may have been hurt. I truly hope not, but I’m not sure how all of this strange behavior on Delta’s part otherwise gets explained.
Thanks for this article, Bob. The biggest thing that stands out to me from the statistics is that anything other than small projects are fraught with peril.
It’s the only size where Agile has better than 50% success, and even Waterfall has a respectable 44% success rate at that size. (Respectable compared to all the other stats, anyway).
Success is more a factor of complexity and competence than methodology, but clearly some methodologies will only exacerbate the other problems.
For now, no comment on Delta other than your well-stated “Near-zero plausibility.”
-ASB
RE: Delta, I can say from observation that bad power is much worse than loss of power. Back in the 1990s I worked in a new building with a massive UPS infrastructure and backup generator, and on two occasions the utility lowered the voltage, causing the UPS to shut down all protected systems while leaving unprotected systems unaffected. If Delta’s equipment in fact caused a power surge via dead short, then equipment could have been damaged up, down, and sideways on the circuit. I would expect effects not entirely dissimilar to airborne metal shavings in the computer room plenum.
80% of new businesses fail within the first 2 years.
I wonder what the success rate of evolution is: how many eggs of a species grow into adults who actually reproduce. Life is hard.
>>>”I wonder what the success rate of evolution is: how many eggs of a species grow into adults who actually reproduce.”
Answer: Anything from one in a hundred thousand for something like carp to most of them, as in many birds.
And humans.